
Corpus Viewer
Resumen de la Plataforma
La plataforma Corpus Viewer se basa en técnicas de procesamiento de lenguaje natural (PLN), aprendizaje automático (ML) y traducción automática (MT) para analizar metadatos estructurados y datos textuales no estructurados en grandes corpus de documentos textuales. La plataforma permite a los responsables de la toma de decisiones e implementadores de políticas la posibilidad de analizar el espacio de información de I+D+i (principalmente patentes, publicaciones científicas y ayudas públicas) para la implementación de políticas basadas en evidencia y conocimiento. Se basa, entre otras técnicas, en el modelado de tópicos y el análisis de grafos.
El desarrollo de Corpus Viewer comenzó en 2016 y sigue avanzando gracias a la colaboración de varios grupos de investigación universitarios y empresas. Corpus Viewer en su versión 1.0 es actualmente utilizado por tres administraciones públicas: SEAD (Ministerio de Economía), la Fundación Española para la Ciencia y la Tecnología (FECYT) y la Secretaria de Estado de Universidades e Investigación, Desarrollo e Innovación (SEUIDI) (Ministerio de Ciencia).
Aunque Corpus Viewer es una plataforma genérica que puede ser explotada con prácticamente cualquier colección de documentos de texto, el despliegue actual de la plataforma aloja principalmente corpus relacionados con el I+D.
Estas fuentes de datos se procesan para ayudar en la definición e implementación de políticas públicas de I+D+i a través de un conjunto de funcionalidades que permiten:
- comparar las áreas de conocimiento y financiación de I+D+i en diferentes regiones geográficas,
- dentificar ventajas competitivas entre países, regiones, organizaciones,
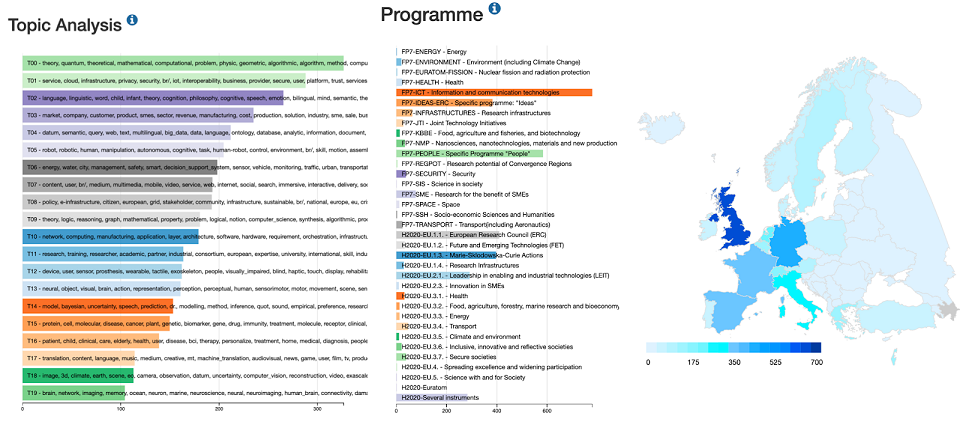
- identificar áreas de conocimiento de I+D+i, así como su emergencia, evolución e incluso hibridación con otras áreas de conocimiento (proporciona también agregación de metadatos y visualización de tablero de instrumentos de tipo BI),
- perfilado de agentes de I+D (organizaciones, investigadores y empresas) y
- ayuda en la evaluación del impacto de las políticas públicas mediante el seguimiento de los resultados de las subvenciones, resultados a corto y largo plazo.
 Corpus Viewer también proporciona herramientas para la implementación de políticas, en particular para la selección de evaluadores o la recuperación de documentos relevantes (patentes, publicaciones científicas, subvenciones y propuestas de I+D para la evaluación de la innovación). Además, se utiliza para la detección de plagio, la identificación de casos de doble financiación y el fraude en subvenciones de ayuda y las propuestas presentadas para la financiación nacional.
Corpus Viewer también proporciona herramientas para la implementación de políticas, en particular para la selección de evaluadores o la recuperación de documentos relevantes (patentes, publicaciones científicas, subvenciones y propuestas de I+D para la evaluación de la innovación). Además, se utiliza para la detección de plagio, la identificación de casos de doble financiación y el fraude en subvenciones de ayuda y las propuestas presentadas para la financiación nacional.
Funciones de Corpus Viewer
- Pipeline de PLN escalable y Traducción automática de grandes volúmenes de documentos.
- Clasificación automática de documentos según taxonomías disponibles empleando redes de aprendizaje profundo (deep learning).
- Modelado de tópicos de colecciones de documentos e inferencia de tópicos para nuevos documentos.
- Sistema de recuperación de información basado en similitud de documentos.
- Indexación optimizada en columnas y texto para búsquedas eficientes y consulltas con filtrado de metadatos.
- Seguimiento de documentos semánticamente semejantes (agrupamientos semánticos) (emergencia, evolución e hibridación con otros grupos).
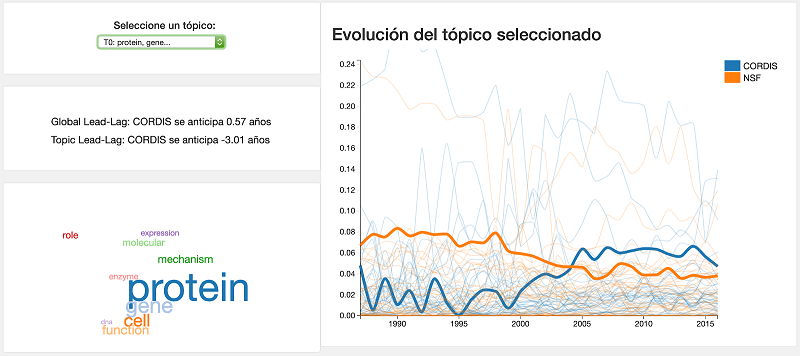
- Análisis dinámico de tópicos y evolución temporal de tópicos. Análisis temporal por áreas de conocimiento, desfase entre diferentes tipos de corpus de documentos.
- Tableros de instrumentos mejorados para analizar la distribución del I+D+i según metadatos, incluida el área geográfica.
- Perfilado automático y desambiguación de los actores clave del I+D+i según su producción.
- Análisis de redes de colaboración
Técnicas empleadas por Corpus Viewer
A diferencia de los métodos de descripción estadística tradicionales, nuestro enfoque no requiere taxonomías predefinidas ni vocabulario controlado. Al contrario, las técnicas de análisis empleadas se basan en la detección automática de los temas subyacentes, la indexación conceptual de documentos, y otras técnicas de representación documental.
- Implementaciones escalables para tokenización, etiquetado PoS, lematización, desambiguación y wikification para los idiomas Inglés y español.
- Traducción automática (ES-EN), basada en métodos neuronales (NMT).
- Modelado de tópicos, incluyendo: modelos estáticos (Latent Dirichlet Allocation, LDA, CTM), modelos de tópicos dinámicos, LDA jerárquico y LDA recursivo.
- Búsqueda de texto y similitud de documentos en base a sus temas, sus representaciones como bolsa de palabras y word embeddings.
- Análisis de grafos, modularidad, distancias entre clústeres y cálculo de centralidad
Usuarios de Corpus Viewer
Los usuarios potenciales de la plataforma actual de Corpus Viewer incluyen:
- Responsables de políticas de I+D
- Gestores y coordinadores de programas de I+D (implementación de políticas)
- Evaluadores de subvenciones y ayudas
- Investigadores, organismos públicos de investigación, empresas
Casos de uso de Corpus Viewer incluyen:
- Diseño de políticas públicas - prospectiva y planificación
- Gestión de convocatorias - clasificación de solicitudes, asignación de evaluadores, similitud de documentos, estimación de la innovación, evaluación y selección de solicitudes
- Seguimiento - seguimiento de resultados de la interveción y medición de su impacto
- Control - alarmas para detección de plagios y patrones de fraude
Demostradores
Existe un demostrador del funcionamiento de la plataforma Corpus Viewer. Toda la información de acceso se encuentra disponible en este enlace.
Descargas
Tríptico Corpus Viewer [PDF] [6.38 MB]
Manual Corpus Viewer [PDF] [2.03 MB]