
Identificador de tendencias en el sector I+D+i
Desarrolladores
El proyecto ha sido desarrollado por grupo de investigación Machine Learning for Data Science (ML4DS) de la Universidad Carlos III de Madrid, y coordinado por Jerónimo Arenas García.
Resumen
El proyecto tiene como objetivo fundamental la construcción de una plataforma para modelado temporal de tópicos que permita detectar temáticas emergentes, desaparición de temáticas, así como la convergencia o divergencia de temáticas. Asimismo, la información contenida en dicha evolución temporal se explotará para la identificación de lead-lag entre diferentes corpus.
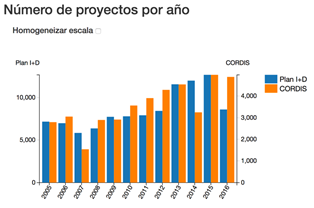
Figura 1. Evolución del número de proyectos en los conjuntos de datos de Plan Estatal y CORDIS
El desarrollo de la herramienta SW pretende proporcionar a Secretaría de Estado para el Avance Digital (SEAD) la posibilidad de entrenar modelos dinámicos de tópicos tanto para los corpus objeto del contrato (artículos científicos, solicitudes de proyectos de investigación y patentes) como para nuevos conjuntos que puedan analizarse en el futuro. La herramienta de Python desarrollada permite entrenar de forma guiada nuevos modelos y exportarlos para su visualización por medio de la herramienta web. Asimismo, la herramienta posibilita el análisis comparativo de corpus de datos para responder a preguntas como:
- ¿cuál es la evolución temporal de la producción científica / patentes / proyectos de investigación según temáticas automáticamente identificadas?
- ¿en qué momento una tecnología disruptiva se hibrida con otras áreas tecnológicas?
- ¿cuál es el adelanto o retraso temático entre los proyectos financiados y los artículos científicos o patentes?
Las principales contribuciones del proyecto son:
- Nuevos algoritmos para el entrenamiento de modelos de tópicos de carácter estático
- Inclusión de una herramienta para el etiquetado automático de tópicos
- Algoritmos para medir la similitud entre tópicos, incluyendo el desarrollo de medidas de distancia semántica entre tópicos basadas en Word Embeddings.
- Algoritmo para el modelado dinámico de tópicos, que proporcionan mejor escalabilidad que otras implementaciones disponibles, y permite el modelado comparativo de diversos corpus y medida del lead-lag
- Herramientas de visualización de los resultados del proyecto
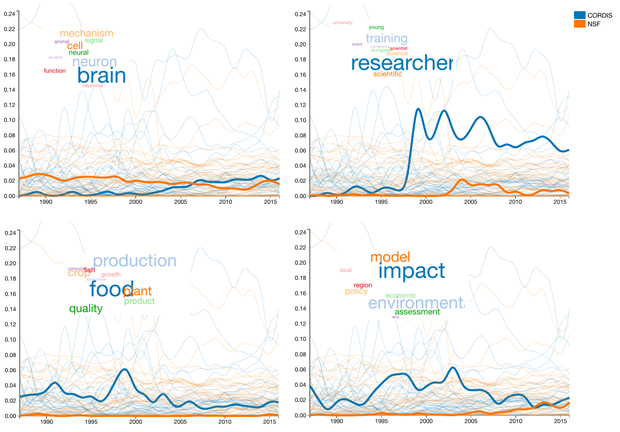
Figura 2. Comparación de la evolución temporal de tópicos para CORDIS y NSF.
La herramienta desarrollada en este proyecto será integrada próximamente dentro de la Plataforma Corpus Viewer para complementar las funcionalidades de análisis de temáticas actualmente disponibles.