
Clasificador de ayudas, publicaciones científicas y patentes
Desarrolladores
Trabajo realizado por el grupo de investigación en Procesamiento del Lenguaje Natural de la Universidad Pompeu Fabra y coordinado por Joan Codina.
Resumen
El objetivo del proyecto es desarrollar clasificadores automáticos para diversos conjuntos de datos, de manera que el clasificador proporcione la clase asociada a un documento a partir del texto no estructurado asociado al mismo. Las clases de salida asociadas a cada clasificador dependen del conjunto de datos empleado para su entrenamiento:
- Área ANEP (26 clases) en el caso del corpus de ayudas del Plan Estatal
- CORDIS Subject Index Classification codes (70) en el caso de Proyectos Europeos
- All Science Journal Classification codes, ASJC (334) para publicaciones científicas
- International Patent Classification codes, IPC (70.000) para patentes
Se pretende explorar con el presente proyecto la capacidad predictiva de las técnicas de procesamiento de lenguaje natural y aprendizaje automático para etiquetar de acuerdo a diferentes taxonomías textos científicos y tecnológicos. Los desarrollos del proyecto son de interés para distintos problemas y colectivos: validación de las selecciones manuales de categorías realizadas por los investigadores, asignación de expertos, generación de etiquetas secundarias, etc.
Los resultados del proyecto son accesibles a través de un servicio web que permite clasificar el texto proporcionado por el usuario según cualquiera de las taxonomías anteriores, por lo que el desarrollo ha prestado especial atención a la escalabilidad del sistema y a la posibilidad de evaluación del clasificador en tiempo real.
Por lo tanto, se ha implementado un servicio de clasificación web según cuatro taxonomías relevantes en el ámbito del I+D+i, bajo restricciones de reusabilidad y escalabilidad, y evaluando las prestaciones del servicio empleando las metodologías de validación cruzada habituales en el ámbito del aprendizaje automático.
El clasificador desarrollado consta de las siguientes etapas de procesamiento:
- Los textos correspondientes a cada documento son indexados (índice Solr basado en Lucene) aplicando un pipeline de procesamiento de lenguaje natural que incluye la detección de n-gramas
- La clasificación de un texto se implementa realizando una búsqueda en el índice Solr de los documentos más cercanos al dado, y aplicando un clasificador basado en K-vecinos más próximos (con valor de K seleccionado mediante validación cruzada)
- El clasificador proporciona un listado de las etiquetas más relevantes junto con una estimación de su probabilidad basada en la distribución de los vecinos
El resultado es un sistema rápido, preciso y de bajo mantenimiento que permite la clasificación automática de documentos y la actualización continua de los modelos con la incorporación de nuevos documentos, una vez la clasificación ha sido revisada.
Las ventajas del clasificador empleado (K-NN) son que no requiere fase de entrenamiento previa, por lo que su actualización resulta inmediata sin más que indexar los nuevos documentos. Tener un sistema autoactualizable es crucial en unos sectores muy dinámicos donde se anuncian, describen y publican por primera vez nuevas investigaciones en todos los ámbitos de la ciencia.
Durante la ejecución del proyecto, el equipo de trabajo evaluó las prestaciones de otros clasificadores y otras parametrizaciones de los documentos (empleando, por ejemplo, Word embeddings y modelos de tópicos), sin encontrar unas mejoras claras en prestaciones que justificase la adopción de estas estrategias más complejas.
De cara a conocer las prestaciones del sistema desarrollado, se han analizado las tasas de error en cada uno de los conjuntos de datos sobre una partición de documentos no indexados previamente. Dado que se trata de taxonomías con un número elevado de clases, y en el que las clases pueden estar relacionadas entre sí, las tasas de error se han analizado según la aparición de la clase correcta entre las primeras predicciones obtenidas por el clasificador.
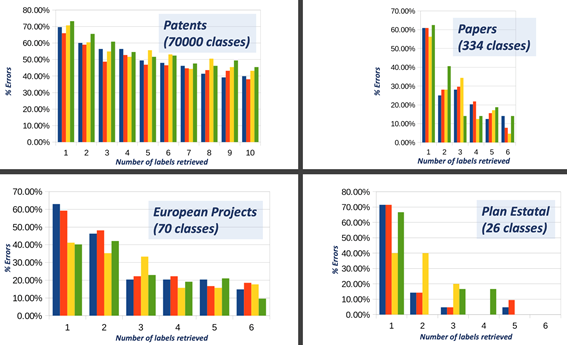
Figura 1. Estimación de prestaciones de los clasificadores entrenados por el proyecto. Cada figura muestra el porcentaje de documentos clasificados erróneamente tomando las N primeras predicciones del clasificador.
A pesar de que en aquellas taxonomías que constan de un número elevado de clases la etiqueta correcta no es siempre la preferida por el clasificador, el análisis detallado de las matrices de confusión muestra que los errores casi siempre ocurren entre clases temáticamente muy relacionadas o en clases con un número muy bajo de documentos disponibles (e.g., en el corpus de patentes existen clases con menos de 10 documentos). Este hecho, junto con la disponibilidad de varias clases de salida y sus probabilidades estimadas hacen de este servicio una herramienta de gran utilidad para investigadores y gestores de programas.
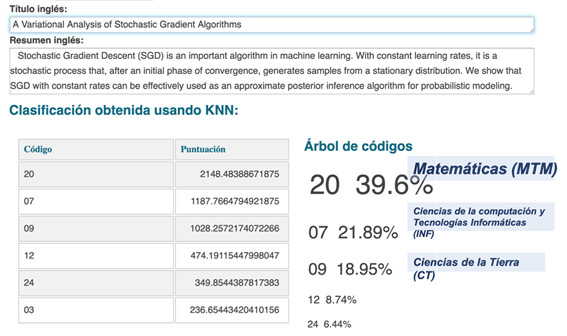
Figura 2. Salida del Servicio Web de Clasificación para área ANEP.